
シャドーライブラリで知られる「Anna’s Archive」が、Spotifyのメタデータと音源ファイルを大規模に収集・アーカイブしたとする調査レポート(ブログ)を公開しました。レポートでは、アーカイブは一括トレント配布(約300TB)で、人気度順にまとめられていると説明しています。
Spotifyでの視聴の約99.6%をカバー
公開されたレポートによると、今回のリリースは「2億5千6百万トラック」「1億8千6百万のユニークISRC」を含む、公開されているものとしては最大級の音楽メタデータDBだとしています。
さらに、音源については約8,600万ファイルを確保し、Spotifyでの視聴の約99.6%をカバーすると主張しています。
一方で、人気度0(長いロングテール)の領域は、費用対効果や品質面を理由に途中で止めたとも記載されています(追加で700TB超が必要になり得る、など)。
どんなデータが含まれ得るか
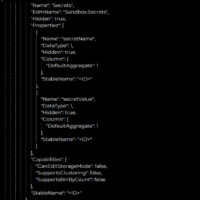
メタデータはアーティスト/アルバム/トラックに加え、プレイリスト情報も含む構成が示されています。プレイリストのテーブル例には、所有者のID(owner_id)や表示名(owner_display_name)といった項目が含まれる形になっており、公開・非公開設定(public)にも言及があります。
つまり、内容次第では「ユーザー識別子に準ずる情報」が含まれ得るため、著作権だけでなくプライバシー観点でも論点になり得ます(※レポートは“公開APIのデータ”として扱っています)。
Spotifyの見解―
この件を報じたCybernewsによると、Spotify広報は、調査の結果として第三者が公開メタデータをスクレイピングし、DRMを回避する不正な手法で一部音源へアクセスした可能性に言及しています(現時点の調査状況として)。
ここで重要なのは、「Spotify内部のシステム侵害(データベース流出)を断定する説明」ではなく、外部者による不正取得(スクレイピング+DRM回避)による可能性を調査しているとしています。
参照
“We backed up Spotify:” pirates claim to have scraped 300TB of music
関連記事
 Anthropic、Claude Codeを悪用した大規模サイバースパイ活動を阻止-中国系 サイバー攻撃 グループか
Anthropic、Claude Codeを悪用した大規模サイバースパイ活動を阻止-中国系 サイバー攻撃 グループか
 企業のAI 導入が招く情報漏洩 リスク-シャドーAIと権限過多が明らかに
企業のAI 導入が招く情報漏洩 リスク-シャドーAIと権限過多が明らかに
 Microsoft Power BI で機密情報を公開する脆弱性を確認
Microsoft Power BI で機密情報を公開する脆弱性を確認
 米 National Public Data(NPD)から130万人の個人情報漏洩
米 National Public Data(NPD)から130万人の個人情報漏洩
 ロサンゼルス郡 フィッシングメールで20万人以上の市民の個人情報漏洩の可能性
ロサンゼルス郡 フィッシングメールで20万人以上の市民の個人情報漏洩の可能性
 岡山県、個別PRサイトで不正アクセス-改ざんを確認し全サイトの公開を一時停止
岡山県、個別PRサイトで不正アクセス-改ざんを確認し全サイトの公開を一時停止
 EDRは約70%が未導入-30%の企業が自社のファームウェアを更新しているか分からない
EDRは約70%が未導入-30%の企業が自社のファームウェアを更新しているか分からない
 ホテルなどの宿泊業を狙う偽ブルースクリーンとClickFix型マルウェアによるサイバー攻撃
ホテルなどの宿泊業を狙う偽ブルースクリーンとClickFix型マルウェアによるサイバー攻撃
 Googleが警告、ShinyHuntersがボイスフィッシング(ビッシング)を起点としてSaaSへ不正アクセス
Googleが警告、ShinyHuntersがボイスフィッシング(ビッシング)を起点としてSaaSへ不正アクセス
