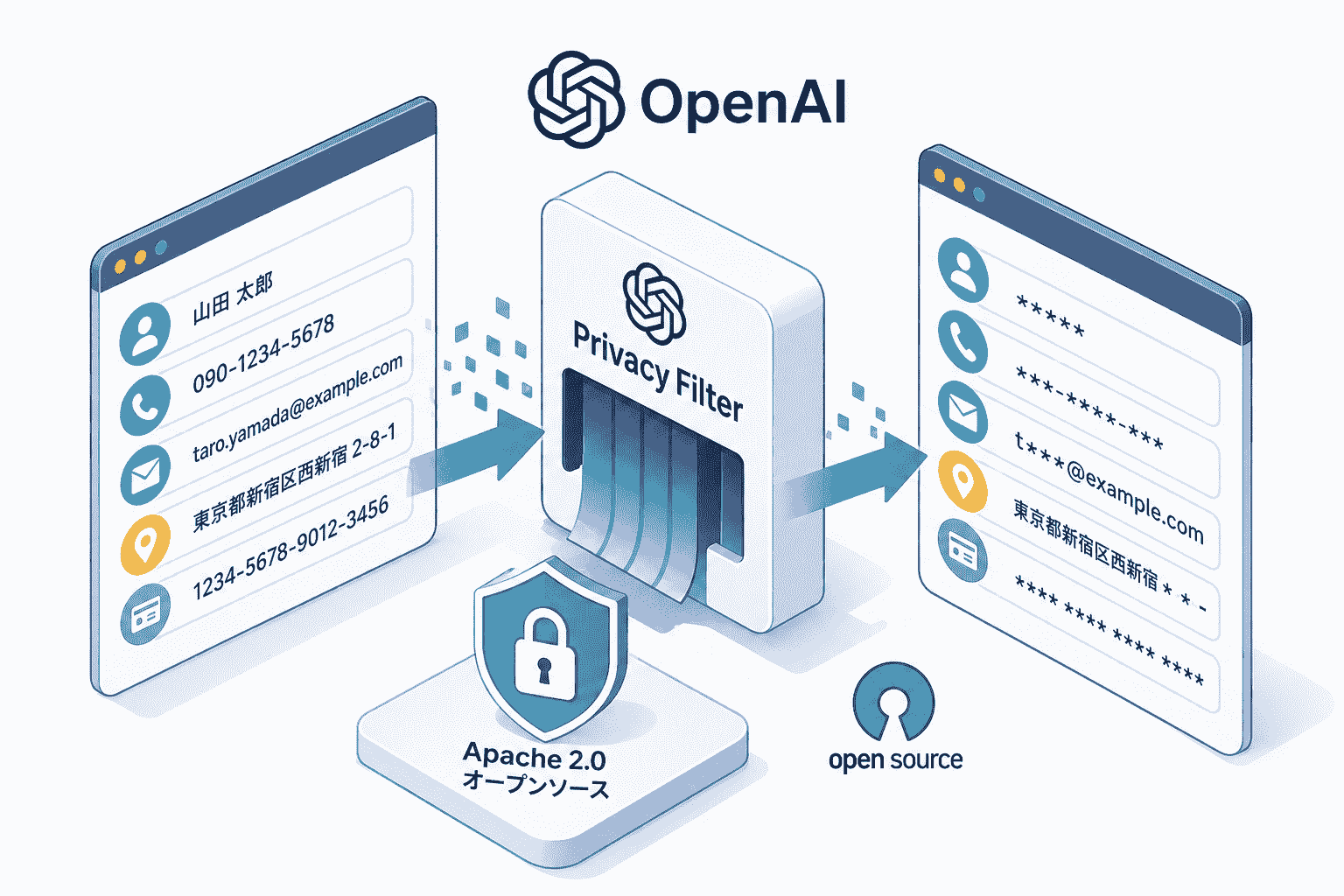
2026年4月22日、OpenAIは個人情報(PII:Personally Identifiable Information)の検出とマスキングを行う専用AIモデル「OpenAI Privacy Filter」を、Hugging FaceおよびGitHubにてApache 2.0ライセンスで公開しました。
総パラメータ数1.5B(アクティブパラメータ50M)のMixture-of-Experts(MoE)アーキテクチャを採用しており、ラップトップやWebブラウザ上でローカル実行が可能です。PII-Masking-300kベンチマークにおいてF1スコア96%を達成しており、OpenAI自身も社内の個人情報保護ワークフローでファインチューニング版を実際に使用しています。
この記事のサマリー
- OpenAIがApache 2.0ライセンスでPII検出・マスキング専用モデルを公開しました。商業利用・カスタマイズ・再配布が自由に行えます。
- 総パラメータ数1.5B・アクティブパラメータ50MのMoEアーキテクチャ。ラップトップ(CPU:RAM 4〜8GB)またはWebブラウザ(WebGPU)でローカル実行が可能であり、データをクラウドに送ることなくPIIの検出・マスキングが完結します。
- 最大128,000トークンのコンテキスト長をサポートし、長文書類を1回のパスで処理します。
- 検出・マスキング対象のPIIカテゴリは8種類:氏名(private_person)・連絡先(private_contact)・メールアドレス(private_email)・電話番号(private_phone)・URL(private_url)・日付(private_date)・口座番号(account_number)・シークレット(secret=パスワード・APIキー等)。
- PII-Masking-300kベンチマークでF1スコア96%(精度94.04%、再現率98.04%)。データセットのアノテーション問題を修正した改訂版では97.43%(精度96.79%、再現率98.08%)を達成。
- **完全な匿名化ツールではなく「マスキング補助ツール」**であることをOpenAI自身が明示しており、高感度な医療・法務・金融ワークフローでは人間によるレビューと組み合わせる必要があります。
Privacy Filterとは何か——「プライバシーのためのスペルチェック」
OpenAIはPrivacy Filterを「スペルチェックのプライバシー版」と表現しています。テキストが入力されると、氏名・住所・メールアドレス・電話番号・URLなどを識別し、出力時にそれぞれ[PRIVATE_PERSON]・[ACCOUNT_NUMBER]などのプレースホルダーに置き換えます。
入力:
"My name is Harry Potter and my email is [email protected]."
出力(検出結果):
[private_person] Harry Potter
[private_email] [email protected]このモデルが解決する本質的な問題は、日々何百万もの人々がChatGPTや他のAIツールに「貼り付けるべきでない情報」
- 確定申告書
- 医療記録
- 業務メール
- クライアント名・APIキー
などが貼り付けられた場合それらを事前にマスキングし、クラウド上のAIモデルに送信される前にローカルで処理を完結させます。
技術的な詳細
アーキテクチャ
Privacy FilterはgptーOSSと同様の双方向トークン分類モデルです。テキストをトークンごとに左右両方向から読み込み(バンドサイズ128、有効注意ウィンドウ257トークン)、1回のフォワードパスでPIIスパンを予測します。出力はBIOES(Begin・Inside・Other・End・Single)スパンタグで表現され、制約付きViterbiデコードによって一貫性のあるスパン境界を生成します。
学習は自己回帰的な事前学習から始まり、その後プライバシー特有のラベル分類のためにファインチューニングされます。このアーキテクチャにより、通常のトークン分類モデルより文脈依存の判断が向上しています。
実行要件
| 環境 | 必要リソース | レイテンシの目安 |
|---|---|---|
| CPU | RAM 4〜8GB(モダンなIntel/AMD) | 1〜2秒/中程度の文書 |
| GPU(FP32) | VRAM 6〜8GB、CUDA 11.8以上 | 0.1〜0.3秒 |
| GPU(FP16) | VRAM 約3GB | 最速 |
| Webブラウザ | WebGPU対応(Chrome/Edgeの最新版) | ブラウザ内でリアルタイム処理 |
8つのPIIカテゴリと検出対象
| カテゴリラベル | 検出対象 |
|---|---|
| private_person | 個人の氏名 |
| private_contact | 住所(物理的な場所) |
| private_email | メールアドレス |
| private_phone | 電話番号 |
| private_url | URL |
| private_date | 日付 |
| account_number | 口座番号・クレジットカード番号・銀行口座番号等 |
| secret | パスワード・APIキー・認証情報等 |
ローカル実行がもたらすコンプライアンス上のメリット
Privacy Filterがローカル実行に対応している点は、企業のコンプライアンス観点から非常に重要な意味を持ちます。クラウドベースのPII検出サービスを使用する場合、企業はサービスプロバイダーとのデータ処理契約(DPA)の締結、越境データフローの評価、法的根拠の文書化、場合によってはデータ保護責任者(DPO)への通知が必要になります。
Privacy Filterがローカルで動作する場合、個人データが組織の境界を越えることがないため、これらの手続きが不要になります。GDPR・HIPAAなどの厳格なデータ保護規制への対応において、クラウドに依存しないローカルファーストのアーキテクチャは重要な差別化要素です。
企業の実用的なユースケースとして、強力なフロンティアモデル(GPT-5・gpt-oss-120b等)への送信前のローカルマスキング、高スループットのデータパイプラインでの前処理、コードベース内のシークレット検出、医療・法務・金融文書の匿名化補助などが想定されています。
限界と注意点——「匿名化の保証ではない」
OpenAIはモデルカードおよびHugging Faceのリリースページで、Privacy Filterの限界を明示しています。
検出漏れが起きやすいケースとして、一般的でない個人名・地域固有の命名規則・イニシャル・敬称のみによる参照・ドメイン固有の識別子が挙げられます。新形式のAPIキー・プロジェクト固有のトークンパターン・コード構文にまたがるシークレットも見落とされやすいとされています。
過剰マスキングが起きやすいケースとして、局所的な文脈が曖昧な場合の公的機関・組織・場所・一般名詞の誤マスキング、高エントロピーの文字列・プレースホルダー・ハッシュ値・サンプル認証情報の誤マスキングが挙げられます。
OpenAIは「Privacy Filterはマスキング補助ツールであり、匿名化・コンプライアンス・安全性の保証ではない」と明示しています。特に医療・法務・金融の高感度ワークフローでは、人間によるレビューとドメイン固有の評価・ファインチューニングが依然として重要です。
開発者向け——導入方法
Hugging Face Transformersを使用する場合(Python):
from transformers import pipeline
classifier = pipeline(
task="token-classification",
model="openai/privacy-filter",
aggregation_strategy="simple",
)
text = "My name is Harry Potter and my email is [email protected]."
result = classifier(text)ブラウザ内で試す場合(transformers.js・WebGPU):
import { pipeline } from "@huggingface/transformers";
const classifier = await pipeline(
"token-classification",
"openai/privacy-filter",
{ device: "webgpu", dtype: "q4" },
);
const output = await classifier(
"My name is Harry Potter and my email is [email protected].",
{ aggregation_strategy: "simple" }
);CLIツール(opf)も提供されており、テキストの直接マスキング・詳細な評価・ファインチューニングに対応しています。Hugging Face Spacesには対話型デモも公開されており、テキストまたはPDFをアップロードしてリアルタイムでマスキング結果を確認できます。
日本企業・開発者への示唆
日本においてもAIツールへの業務情報の入力に関するガイドラインの整備が進んでいますが、現場での運用では依然として個人情報や機密情報のAIツールへの入力が行われているのが実態です。Privacy Filterのようなローカル実行可能なPIIマスキングツールをAIワークフローの前段に組み込むことで、組織的な「情報漏洩のリスクを減らす仕組み」として活用できる可能性があります。
特にApache 2.0ライセンスで商業利用・カスタマイズが自由に行えること、比較的低スペックのマシンでローカル実行が可能なこと、そしてファインチューニングにより日本語特有の個人情報の表現形式(氏名・住所等)への対応精度を向上できる点は注目に値します。
よくある質問(FAQ)
Q. Privacy Filterは日本語に対応していますか? OpenAIの公式発表では多言語テキストへのストレステストが実施されているとされています。ただし学習データの分布により、英語以外の言語では精度が下がる可能性があります。日本語固有の氏名・住所形式への対応精度向上にはファインチューニングが推奨されます。
Q. 商業利用は可能ですか? はい。Apache 2.0ライセンスのため、商業利用・カスタマイズ・再配布が自由に行えます。
Q. Privacy Filterを使えば個人情報の取り扱いが完全に安全になりますか? なりません。OpenAI自身が「匿名化・コンプライアンス・安全性の保証ではない」と明示しています。特に高感度な業務では、Privacy Filterを多層的なプライバシー保護アプローチの一つの層として使用し、人間によるレビューを組み合わせることが必要です。
Q. GPUがなくても動作しますか? はい。CPUのみでもRAM 4〜8GBあれば動作します。中程度の文書で1〜2秒のレイテンシが見込まれます。
参考情報
- Introducing OpenAI Privacy Filter(OpenAI公式、2026年4月22日)
- openai/privacy-filter(Hugging Face)
- openai/privacy-filter(GitHub)
- OpenAI Privacy Filter Model Card(PDF)
- OpenAI launches Privacy Filter(VentureBeat、2026年4月22日)
関連記事
 Pythonのtarfileモジュールに深刻な脆弱性(CVE-2024-12718)
Pythonのtarfileモジュールに深刻な脆弱性(CVE-2024-12718)
 Hugging FaceでAIのバックドア 付き 機械学習モデルを確認
Hugging FaceでAIのバックドア 付き 機械学習モデルを確認
 Windows Cloud Files Mini Filter Driver の脆弱性を悪用するPoCエクスプロイトが公開(CVE-2020-17136,CVE-2025-55680)
Windows Cloud Files Mini Filter Driver の脆弱性を悪用するPoCエクスプロイトが公開(CVE-2020-17136,CVE-2025-55680)
 OpenAI「GPT-5.4-Cyber」をセキュリティチーム向けにリリース|Anthropic「Claude Mythos」との戦略的差異・効果・アクセス方法を解説
OpenAI「GPT-5.4-Cyber」をセキュリティチーム向けにリリース|Anthropic「Claude Mythos」との戦略的差異・効果・アクセス方法を解説
 Google、Chrome 141の安定版で2件の危険性の高い脆弱性(CVE-2025-11205,CVE-2025-11206)を含む21件の脆弱性を修正
Google、Chrome 141の安定版で2件の危険性の高い脆弱性(CVE-2025-11205,CVE-2025-11206)を含む21件の脆弱性を修正
 政府、牧野フライス製作所へのMBKパートナーズ買収を外為法で中止勧告—重要技術流出防止と経済安全保障の最前線【2026年最新】
政府、牧野フライス製作所へのMBKパートナーズ買収を外為法で中止勧告—重要技術流出防止と経済安全保障の最前線【2026年最新】
 Pythonのパッケージ「llama_cpp_python 」で重大な脆弱性(CVE-2024-34359)
Pythonのパッケージ「llama_cpp_python 」で重大な脆弱性(CVE-2024-34359)
 可用性とは何か?リスクと対策を事例とともに解説
可用性とは何か?リスクと対策を事例とともに解説
 市立奈良病院にサイバー攻撃—が大規模なシステム障害で電子カルテが停止し救急・外来診療を休止
市立奈良病院にサイバー攻撃—が大規模なシステム障害で電子カルテが停止し救急・外来診療を休止
